
[Research] How PPO Works in Language Model
Published:
Language Model에서 PPO가 동작하는 방법
Reinforcement Learning
Policy Gradient
Policy network \(\pi_{\theta}\)를 학습하기 위해서 환경에서 경험을 쌓고, 그 경험을 바탕으로 \(\pi_{\theta}\)를 발전시키고자 한다. 신경망의 파라미터를 업데이트를 할 때는 기본적으로 gradient descent 방법을 사용하기에, policy network를 학습하기 위해 loss를 정의해야 한다. 하지만, loss를 정의하려면 정답이 정의되어야 하지만, policy의 정답이란 곧 최적의 policy을 의미하게 되는데, 최적의 policy를 안다면 강화 확습을 할 필요가 없다. 따라서, 정답과의 loss를 줄이는 방식이 아니라, policy를 평가하는 기준을 세운 뒤, 그 값을 증가하는 방향으로 학습하고자 한다. 이러한 방법을 gradient ascent라 한다.
따라서 \(\pi_{\theta}(s, a)\)를 평가하는 함수 $J(\theta)$를 정의하고, 해당 값을 증가시키면 된다. 계속해서 $\theta$를 업데이트하면 \(\pi_{\theta}\)(s, a)의 평가가 높아지게 되고, 이것이 곧 강화학습이다.
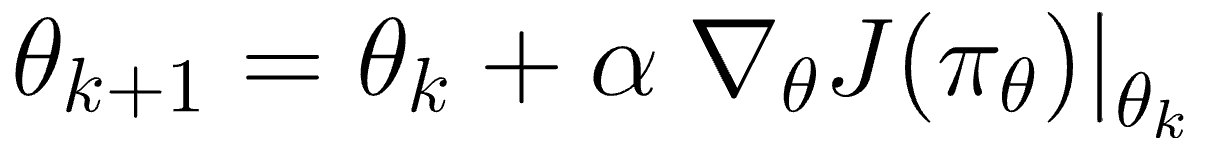
Policy $\pi$가 고정되어도 에피소드마다 다른 state를 가고, 다른 reward를 얻기에 최종 $J(\theta)$는 reward의 총합의 기댓값으로 볼 수 있다.

따라서, 최종적으로 밑의 수식을 최대화하는 것이 강화학습의 목적이다.
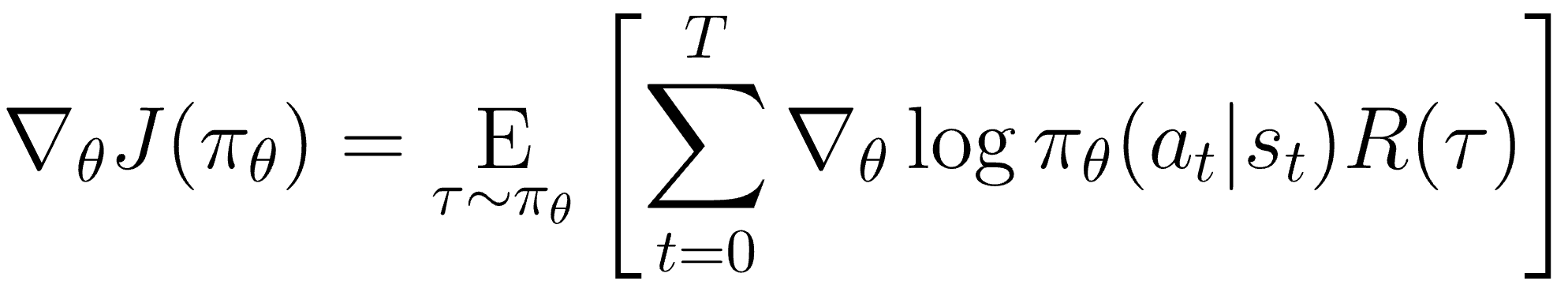
Actor-Critic
위의 식에서 reward $R$이 critic $Q$로 표현하면 actor-critic이라 한다. 하지만 해당 방법에도 문제점이 있는데, 만약 미래 모든 reward가 양수라면 어떤 방향으로 가던 policy가 좋아지게 되는데, 이렇게 되면 최적의 방향으로 가지 못할 수 있다. 따라서 $Q$에서 각 state의 value $V$를 빼주는 Advantage를 도입한다. Advantage를 통해 특정 action이 얼마나 효과적이었는 지를 평가할 수 있다.
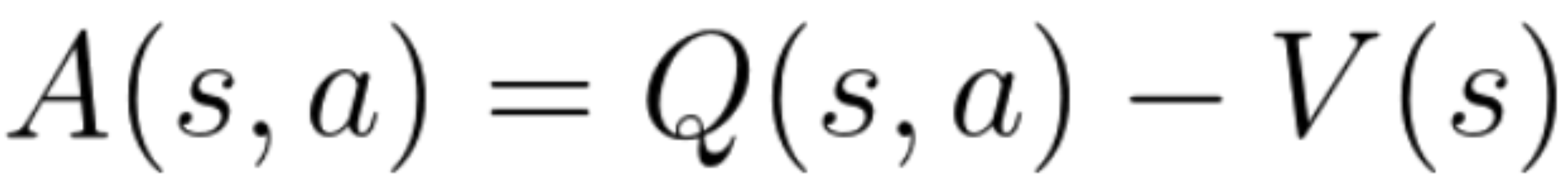
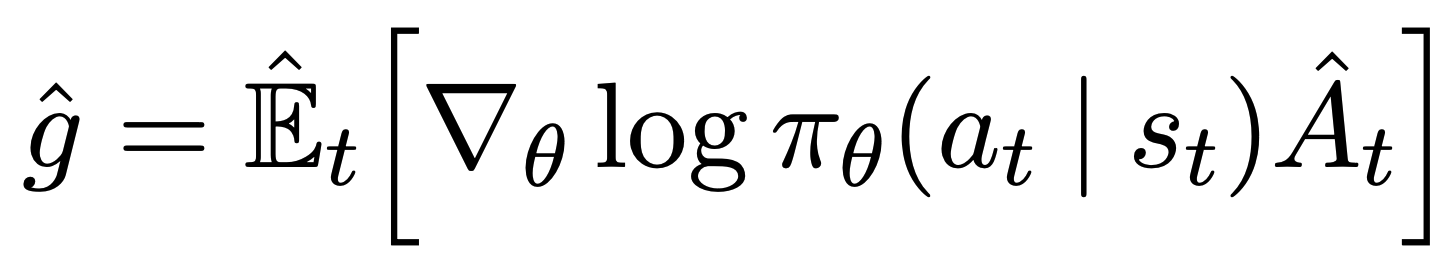
Proximal Policy Optimization Algorithms (PPO)
PPO는 Actor-Critic 모델 중 하나로, TRPO (Trust Region Methods)의 단점을 개선한 모델이다.
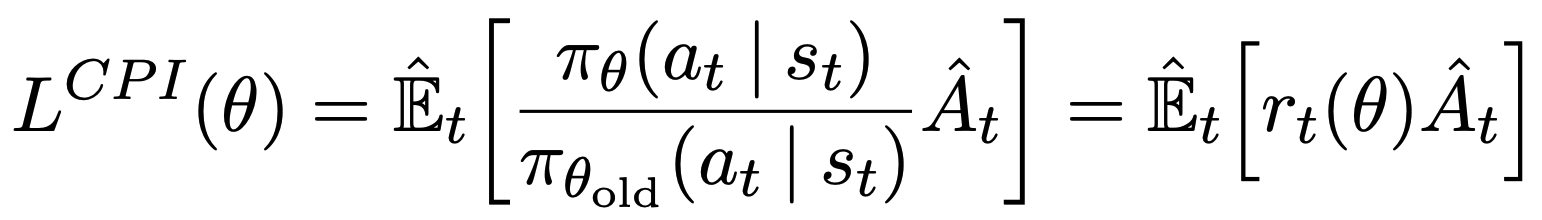
CPI는 conservative policy iteration을 의미하며, constraint가 없다면 policy 업데이트가 너무 커지기 때문에 PPO에서는 clipping과 함께 사용한다. Clipping을 통해 너무 커지거나 너무 작아지지 않도록 조절한다.
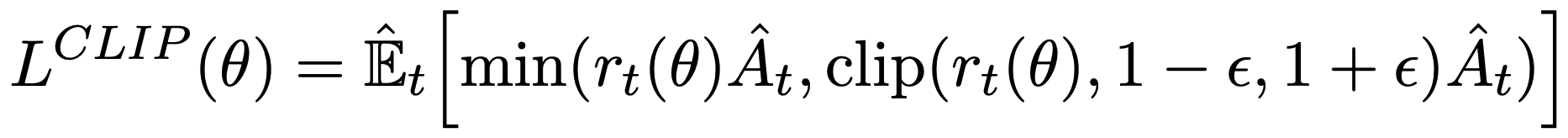
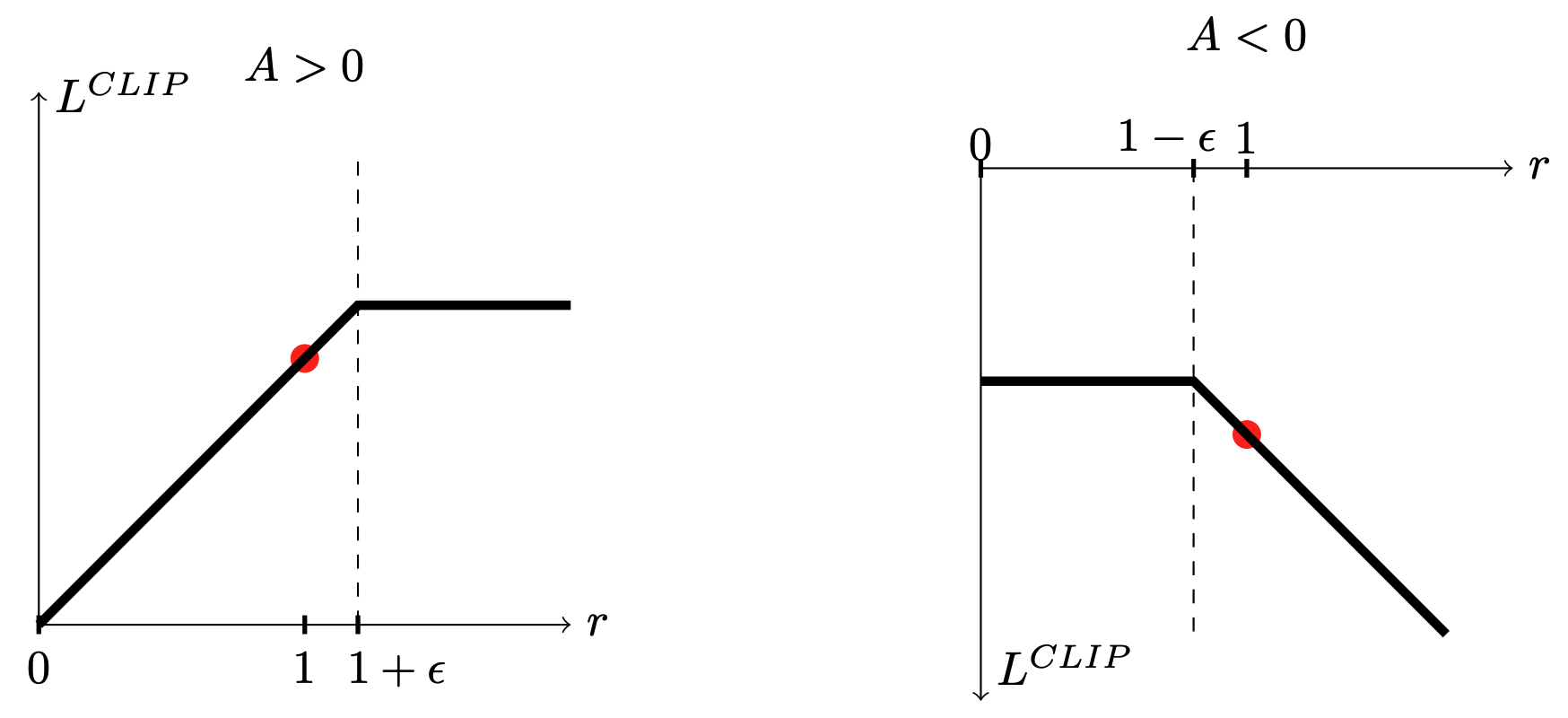
Value function으로는 squared-loss를 사용한다.
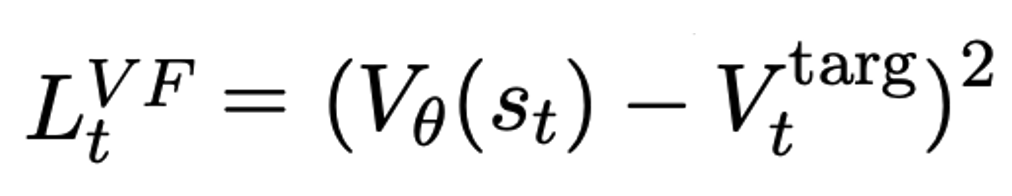
따라서, 최종 PPO loss는 아래와 같다.
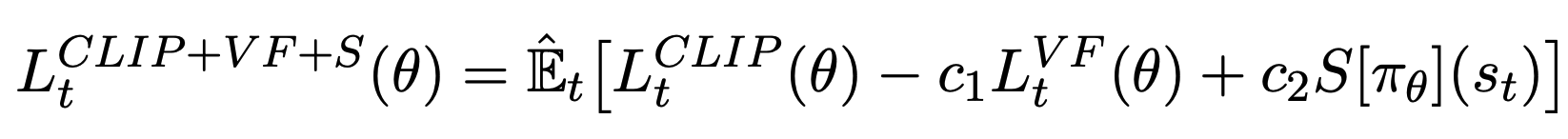
또한, PPO의 loss function은 각 time step마다 advantage 함수를 계산해야 하는데, 이때 T는 전체 episode보다 훨씬 작다.

Language Model with PPO in Summarization Task
Advantage function을 계산할 때는 r이 필요하다. r은 각 timestep의 reward를 의미하기에, language model에서의 reward란 생성한 각 token에 대한 reward를 의미한다. 하지만 summarization과 같은 task에서 reward로 ROUGE 점수를 준다고 가정하면, ROUGE는 전체 요약문에 대한 점수이기에 각 token별로 reward를 제공할 수 없다.
따라서, 이러한 경우 전체 output sequence에 대한 reward를 해당 sequence 안의 각 토큰 reward로 사용한다.


하지만, 이렇게 output sequence의 모든 토큰에 대한 reward를 전체 output sequence의 reward로 주게 된다면, 원하지 않는 결과가 나올 수 있다. 따라서, 현재 policy가 original model에서 너무 멀리 떨어지지 않도록 하기 위해, 각 토큰에 대한 policy와 reference model (frozen)의 KL penalty를 추가한다. 결국 토큰의 최종 reward는 전체 sequence에 대한 reward (이 경우 ROUGE) + KL penalty이다.
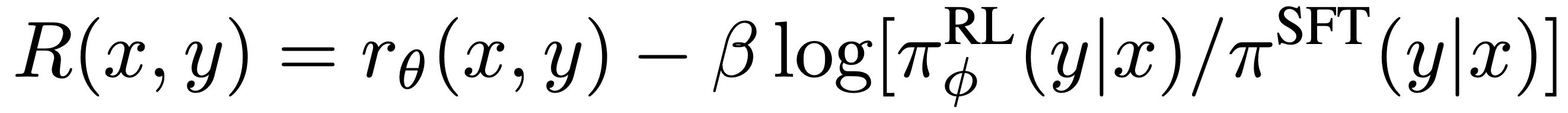
Value Function
그럼 이번에는 language function의 value function을 estimate하는 과정을 알아본다. PPO에서 value function을 estimate할 때, target과 prediction에 대한 squared-error를 사용하는데, language model에서 PPO를 사용할 때는 token의 hidden-state가 linear head를 통과한 scalar value이다. 따라서, language model에서의 value function loss는 $(value - return)^{2}$이 된다. 최종적으로는 clipped된 value 중 큰 값으로, $vf$_$loss = 0.5 * max((value - return)^{2}, (clipped$_$value - return)^{2})$이다.
정리
Value: 각 토큰의 hidden dimension이 linear head를 통과한 scalar 값.
Reward: 전체 sequence의 score (ROUGE).
Advantage: 미래 시점까지의 Reward 합에서 현재 state에서의 Value를 뺀 값.
Return: Advantage + Value, 곧, 각 value에 reduction factor $\gamma$를 곱해서 더한 값.
Action probability: Policy의 다음 token probability Action space: Policy의 vocabulary
Comments
NLP에서 PPO를 적용할 때, $value$ function을 예측하기 위해서 각 토큰의 hidden dimension이 linear head를 통과한 scalar값을 사용하는데, 해당 scalar 값이 실제 value function을 예측할 수 있는 지에 대한 의구심이 들었다. 만약 $reward$로 ROUGE 점수를 준다면, 각 토큰에 대한 $reward$는 KL penalty이고 마지막 생성한 토큰에 대한 $reward$가 ROUGE 값일 것이다. 따라서, $return$은 discount factor를 적용한 에피소드의 총 $reward$ 합일 것이고, 이 값이 곧 hidden dimension이 linear head를 통과한 scalar값이 곧 예측한 $value$이 된다. 해당 linear layer가 value를 예측할만한 충분한 정보를 담을 수 있을까?
Reference
바닥부터 배우는 강화학습, 노승은, 영진닷컴
단단한 심층강화학습, 로라 그레서, 제이펍
Proximal Policy Optimization Algorithms, John Schulman, arXiv 2017
Learning to summarize from human feedback, Nisan Stiennon, NeurIPS 2022
OpenAI Spinning Up
HuggingFace TRL Library